The Dot Product Program Revisited
Did you try and fix the Dot Product program from the last post? How successful were you? As you get used to Epiphany programs, it will get easier to debug and write your own. For now, it’s best that whenever you write your own programs, you always start from an existing Epiphany program and slowly make changes.
Recall that we want to calculate the sum of products of two vectors containing the elements between 0..N-1, for some value of N (Assume N is a power of 2, and N >= 16. To do this, we make the following observations:
- The
e_task.cprogram does not need to change. While we are updating the original values in the array, the actual array operations that occur on each individual core stay the same. - No changes need to be made to
build.shorrun.sh. - We need to update
common.hto specify our number of cores. - We need to update
main.cto support genericN, and make the necessary changes to support non-unit arrays. - For the series that we are interested in, observe that the sum of products of two vectors containing the elements 0..N-1 can be defined as:
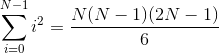
Fixing the Dot Product program
For the initial example, let’s pick N=64. Using the above equation, the
sum of products should be 85344.
First let’s update common.h to be the following:
#define N 64
#define CORES 16The updated main.c now looks like the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
#include <stdlib.h>
#include <stdio.h>
#include <e-hal.h>
#include "common.h"
#define RESULT 85344
int main(int argc, char *argv[]){
e_platform_t platform;
e_epiphany_t dev;
unsigned a[N], b[N], c[CORES];
unsigned done[CORES],all_done;
unsigned sop;
int i,j;
unsigned sections = N/CORES; //assumes N is evenly divisible by CORES
unsigned clr = 0;
//Calculation being done
printf("Calculating sum of products of two integer vectors of length %d inital
ized to 0..%d using %d Cores.\n",N,N-1,CORES);
printf("........\n");
//Initalize Epiphany device
e_init(NULL);
e_reset_system(); //reset Epiphany
e_get_platform_info(&platform);
e_open(&dev, 0, 0, platform.rows, platform.cols); //open all cores
//Initialize a/b input vectors on host side
for (i=0; i<N; i++){
a[i] = i;
b[i] = i;
}
//1. Copy data (N/CORE points) from host to Epiphany local memory
//2. Clear the "done" flag for every core
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_write(&dev, i, j, 0x2000, &a[(i*platform.cols+j)*sections], sections*sizeof(unsigned));
e_write(&dev, i, j, 0x4000, &b[(i*platform.cols+j)*sections], sections*sizeof(unsigned));
e_write(&dev, i, j, 0x7000, &clr, sizeof(clr));
}
}
//Load program to cores and run
e_load_group("bin/e_task.srec", &dev, 0, 0, platform.rows, platform.cols, E_TRUE);
//Check if all cores are done
while(1){
all_done=0;
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_read(&dev, i, j, 0x7000, &done[i*platform.cols+j], sizeof(unsigned));
all_done+=done[i*platform.cols+j];
}
}
if(all_done==CORES){
break;
}
}
//Copy all Epiphany results to host memory space
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_read(&dev, i, j, 0x6000, &c[i*platform.cols+j], sizeof(unsigned));
}
}
//Calculates final sum-of-product using Epiphany results as inputs
sop=0;
for (i=0; i<CORES; i++){
sop += c[i];
}
//Print out result
printf("Sum of Product Is %u!\n",sop);
//Close down Epiphany device
//Close down Epiphany device
e_close(&dev);
e_finalize();
if(sop==RESULT){
return EXIT_SUCCESS;
}
else{
return EXIT_FAILURE;
}
}
Let’s break down this program into sections, calling to attention the salient changes in each:
The header section
Most of the changes to the first 22 lines of the program largely increase the
consistency between the main.c and e_task.c programs, while gaining us an
additional bit of storage.
#include <stdlib.h>
#include <stdio.h>
#include <e-hal.h>
#include "common.h"
#define RESULT 85344
int main(int argc, char *argv[]){
e_platform_t platform;
e_epiphany_t dev;
unsigned a[N], b[N], c[CORES];
unsigned done[CORES],all_done;
unsigned sop;
int i,j;
unsigned sections = N/CORES; //assumes N is evenly divisible by CORES
unsigned clr = 0;
//Calculation being done
printf("Calculating sum of products of two integer vectors of length %d inital
ized to 0..%d using %d Cores.\n",N,N-1,CORES);
printf("........\n");- Our header files are the same
- We define
RESULTto hold the result of the sum of products operation. Recall that ifNis64, the sum of products should be85344. - We change most of the
inttypes tounsignedto gain an extra bit of storage, and increase consistency wtih thee_task.cfile. This is useful, since our program can now handleNvalues of between16and1024. - We define a new variable called
sectionswhich represents the size of of each chunk that is written to every core immediately prior to the local sum of products calculation. - We simplify the declaration of
clr. Much cleaner. - We change the
printfstatement to reflect the new type of operations we are performing.
Initializing and transferring data to the device
In the next part of the code, we update the values of our a and b arrays,
and update the way we write data to the device. This section of code represents
the most critical of the changes.
//Initalize Epiphany device
e_init(NULL);
e_reset_system(); //reset Epiphany
e_get_platform_info(&platform);
e_open(&dev, 0, 0, platform.rows, platform.cols); //open all cores
//Initialize a/b input vectors on host side
for (i=0; i<N; i++){
a[i] = i;
b[i] = i;
}
//1. Copy data (N/CORE points) from host to Epiphany local memory
//2. Clear the "done" flag for every core
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_write(&dev, i, j, 0x2000, &a[(i*platform.cols+j)*sections], sections*sizeof(unsigned));
e_write(&dev, i, j, 0x4000, &b[(i*platform.cols+j)*sections], sections*sizeof(unsigned));
e_write(&dev, i, j, 0x7000, &clr, sizeof(clr));
}
}
//Load program to cores and run
e_load_group("bin/e_task.srec", &dev, 0, 0, platform.rows, platform.cols, E_TRUE);- There is no change to the way we initialize the epiphany platform and establish the workgroup. Again, this will be largely unchanged from host program to host program.
- We modify the arrays
aandbsuch that theith element is set equal to the valuei. In this manner, the arraysaandbare respectively set to the values 0..N-1. - Our two
e_writestatements contain the most significant of the changes. Notice what we are writing to each respective memory bank is now the chunk ofaandbstarting at the position(i*platform.cols+j)*sections. In essence, the portion(i*platform.cols+j)acts as a counter that goes from 0..CORES, whilesectionsweighs the counter by the size of each chunk. Notice also that what gets written to each memory bank is a number of bytes equivalent tosectionselements, as specified bysections*sizeof(unsigned).
Waiting for the device program to finish, and copying local results
The next part of the code does not have any significant changes:
//Check if all cores are done
while(1){
all_done=0;
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_read(&dev, i, j, 0x7000, &done[i*platform.cols+j], sizeof(unsigned));
all_done+=done[i*platform.cols+j];
}
}
if(all_done==CORES){
break;
}
}
//Copy all Epiphany results to host memory space
for (i=0; i<platform.rows; i++){
for (j=0; j<platform.cols;j++){
e_read(&dev, i, j, 0x6000, &c[i*platform.cols+j], sizeof(unsigned));
}
}- The major change here is that we check if
all_doneis equal toCORESrather than16. Again, this will assist in our program maintaining correctness as we change the number ofCORES. - Notice that we change the
sizeof()function parameter tounsignedfromint. This is actually unnecessary, and is done for stylistic reasons. Please note that bothunsignedandintare 4 bytes. Therefore, there is no difference in passingintorunsignedto thesizeof()function.
Calculating and printing the result, and finalizing the program.
Again, there are very few changes to this last section of code:
//Calculates final sum-of-product using Epiphany results as inputs
sop=0;
for (i=0; i<CORES; i++){
sop += c[i];
}
//Print out result
printf("Sum of Product Is %u!\n",sop);
//Close down Epiphany device
//Close down Epiphany device
e_close(&dev);
e_finalize();
if(sop==RESULT){
return EXIT_SUCCESS;
}
else{
return EXIT_FAILURE;
}
}- We change the
ifstatement to check ifsopis equal toRESULT, which we defined at the top ofmain.c. Nothing else changes.
If you run your program with different values of N and RESULT, you should
see that this version of the program works. As a reminder, the way to run
the program is to do the following:
cd ~/epiphany-examples/apps/dotproduct
./build.sh
cd bin
../run.shIn Class Exercises
Exercise 1
- Try and run this program on the
Nvalue of2048. Does the program break? If so, how do you fix it? - Can you change the program to support an
Nvalue of4096?
Exercise 2
- Update the program so that
aandbcontain random integers between1and100. Remove the checks in therun.shandmain.cfiles, and simply output the result.